miller
Command-line data processing tool for CSV, TSV, JSON, and JSON Lines with field-based operations
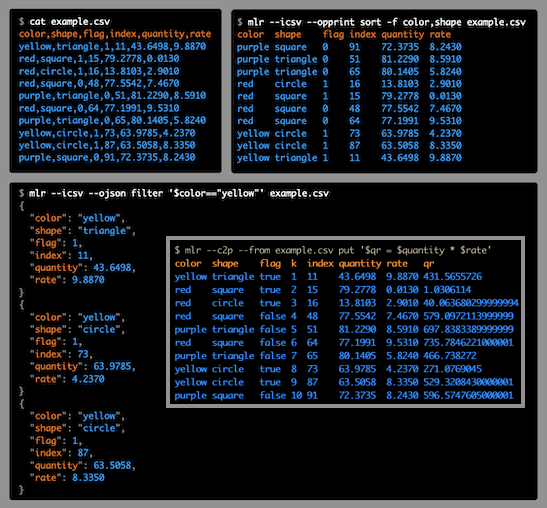
Miller is a command-line data processing tool that operates on structured data formats including CSV, TSV, JSON, JSON Lines, and positionally-indexed data. It functions like traditional Unix tools (awk, sed, cut, join, sort) but works with named fields rather than positional indices, making it suitable for modern data formats where field names matter.
The tool supports field manipulation operations such as adding computed fields, dropping columns, sorting, statistical aggregation, and format conversion. Miller handles heterogeneous records where different rows can have different schemas, which is common in NoSQL and log data. It processes data in a streaming fashion, keeping only one record in memory at a time for most operations, enabling it to work with datasets larger than available RAM.
Miller targets data analysts, DevOps engineers, and system administrators who need to clean, transform, or analyze structured data from the command line. It complements data analysis tools like R and pandas by preprocessing data before loading into memory-intensive frameworks. The tool integrates with Unix pipelines and supports format-aware operations like keeping CSV headers when sorting.
Installation
# via Homebrew
brew install miller
# via APT
apt-get install miller
# via Go
go install github.com/johnkerl/miller/v6/cmd/mlr@latest